
At the moment, data science is one of the most valuable skills in the computer industry. However, it can take time to comprehend how to use data science to design a solution. To execute your projects like a future data scientist, you must be keenly interested in understanding how the data science project life cycle functions.
Today, we’ll go over how any data science project would be implemented in the real world, step by step.
📌 Table of Contents
What is a Data Science Life Cycle?
The data science lifecycle process is the steps and activities followed to turn data into meaningful insights. It typically includes tasks such as data collection, data preparation, data exploration, model building, model deployment, and model maintenance.
It is important to ensure data quality is maintained throughout the process to produce accurate results. All of these steps together form a complete Data Science Life Cycle.
The entire process entails a lot of processes, including data preparation, cleaning, modelling, model evaluation, etc. It is a drawn-out process that could take several months to finish. Therefore, having a general structure to follow for any problem at hand is crucial.
Why is the life cycle of data science projects essential?
A Data Science project typically has data as its primary component. We can analyse and make predictions with data because we are examining uncharted territory. As a result, before beginning any data science project that we have received from one of our clients or a stakeholder, we must first comprehend the underlying problem statement that was supplied.
After understanding the business issue, we must collect the necessary information to resolve the use case. However, many queries come up for newcomers, such as:
- What format are the data needed in?
- How do I obtain the data?
- What should we do with the data?
There may be numerous questions, but each person will likely have different answers. We have created a process called the Data Science Project Life Cycle to handle each of these problems methodically.
To prepare data, a corporation must gather, clean, and execute EDA to extract pertinent features and perform feature engineering and scaling.
The model is constructed and deployed in the second step once it has been evaluated. The entire team must cooperate to complete the project with the needed level of efficiency.
📌 Relevant read: Top data science companies based in Bangalore
What are the six stages of the data lifecycle?
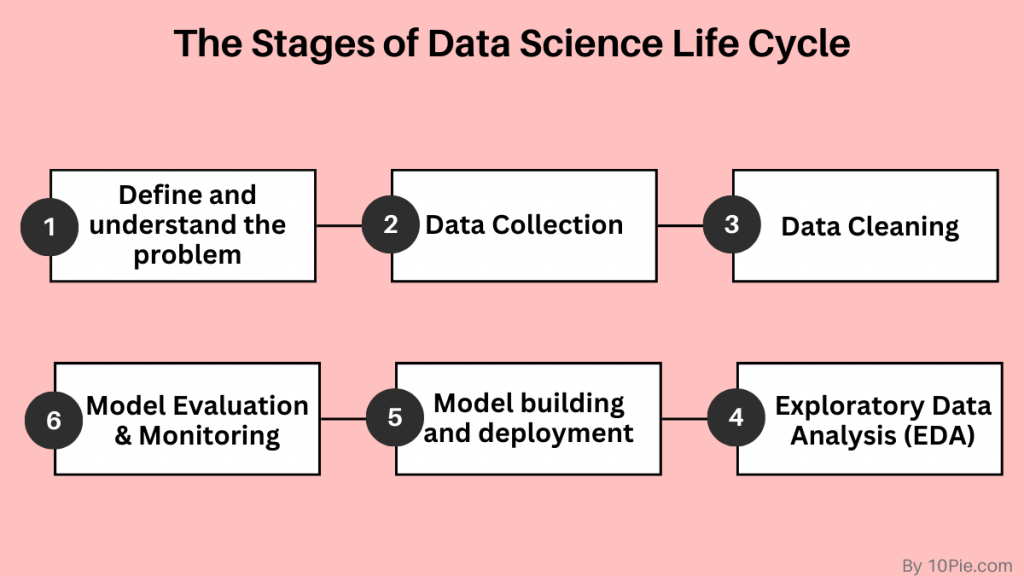
The data lifecycle, which includes all project stages from beginning to end, describes data science projects. It consists of each step, from gathering data to applying and monitoring data.
Data scientists may better manage their projects and ensure they are utilising the best practices for each stage by understanding the various stages of the data lifecycle.
Phase 1: Define and understand the problem
Data scientists define the issue they are attempting to resolve and comprehend the project’s goals during this phase. They specify the stakeholders impacted by the project and the data they will need to gather. The data lifecycle begins with this phase, which is also the most crucial.
Data scientists will define the problem statement that will direct the project goals and objectives during this phase—identifying the goals and inquiries that each stakeholder wants to address may include collaborating with them.
The data they will need to gather will also be identified, along with where to find it and any applicable restrictions or limitations. Data scientists can ensure that they are working on the ethical problem and have the data they need to solve it by clearly grasping the situation and the data requirements.
It’s also crucial to note that during this phase, data scientists identify any legal and ethical concerns that might be connected to the data and the project, such as data privacy and security. They ensure that the data is collected in a manner that complies with all applicable legal and ethical standards.
Phase 2: Data Collection
Data scientists gather the necessary information to address the issue at this phase. This might entail collecting information from various databases, spreadsheets, or APIs. Data analysts must determine what information is required and pertinent for the project.
After being gathered, the data is saved to make it easy to access and examine.
Various methods can be used to collect data, including online scraping, leveraging APIs to access data, and conducting surveys of people.
Data collection is essential since the data’s relevance and quality will immediately impact the precision and dependability of the analysis and modelling. Data scientists must gather enough quality data to support their modelling and analysis.
📌 Related resources on data science:
- Learn the complete guide to start your data science career
- What exactly is data curation in data science?
Phase 3: Data Cleaning
Data preparation for analysis involves cleansing the data. It entails eliminating redundant or unrelated data, adding missing numbers, and fixing mistakes. To use the data for analysis, it must be ensured that it is accurate and consistent.
Data cleaning guarantees that the data is trustworthy and reliable for future analysis, making it a vital phase in the data lifecycle. Data scientists will carry out a range of tasks throughout this stage, including:
- Removing duplicate data
- Handling missing or null values
- Identifying and correcting errors in the data
- Formatting data consistently
- Removing outliers
Data scientists may need to go through several cleaning rounds to ensure the data is correct and consistent, making data cleaning a time-consuming and iterative process. Tasks like eliminating outliers, standardising measuring units, or transforming data kinds can fall under this category.
Phase 4: Exploratory Data Analysis (EDA)
Data scientists examine the data during this stage to gain insights and spot patterns. This can entail analysing the data visually, performing statistical analyses, and developing models. The objectives are to understand the data and identify areas requiring additional research.
Exploratory data analysis (EDA) is a critical stage in the data lifecycle since it aids in seeing patterns, trends, and insights in the data that might not be immediately apparent. Data scientists will carry out a range of tasks throughout this stage, including:
- Creating visualisations of the data to identify patterns and trends
- Performing statistical tests to determine relationships between variables
- Investigating outliers and anomalies in the data
- Identifying any missing or corrupt data
Statistical tests are another crucial component of EDA. They enable data scientists to discover connections between variables and evaluate data-related hypotheses.
Data scientists may need to switch back and forth between several jobs, such as cleaning and displaying the data, during the iterative process of EDA to comprehend the data better.
Phase 5: Model building and deployment
Data scientists create models to address the problem they have identified during this stage. This may entail a simulation, a statistical model, or training a machine learning model. Developers develop, test, and use the model in the real world.
Data scientists will subsequently use the data to train and improve the model throughout this stage.
After training and optimisation, the model is tested to see if it can correctly predict outcomes from new, untested data. The data may be separated into a test/trial set and a training set, and the model’s effectiveness on the test set may be assessed.
The model is implemented in the real world after being tested and validated. This may entail utilising the model to generate predictions in a production setting or integrating it into a web or mobile application.
It’s crucial to remember that developing and deploying a model is iterative because it will continually be updated and enhanced over time.
Phase 6: Model Evaluation and Monitoring
Finding the most effective way among the many techniques and methodologies used in data modelling is crucial. The phase of model evaluation and monitoring enters the picture at this point. It is essential for assuring the model’s correctness and dependability.
Real-world data is used to evaluate the model, and its performance is closely examined for growth. The output of the model may also alter as the data evolves. To keep the model accurate and valuable, it is crucial to assess it and make changes as needed periodically.
Final words
Various tools and strategies are used in the rapidly expanding discipline of data science to draw conclusions and information from data. Data science employs many methods and tools, such as machine learning, statistical analysis, and data visualisation. Check out our data science category page if you’re interested in learning more about data science and the many methods and equipment employed in the discipline.
FAQs
Is data science still in demand in 2023?
Data science is still in demand because businesses rely on data-driven insights to guide decision-making and spur corporate expansion. The necessity for data scientists and other experts to evaluate and interpret this data will only increase as more data is produced and collected.
Does data science need coding?
Strong coding/knowledge abilities are necessary to work in the data science field. Data scientists utilise machine learning or artificial intelligence algorithms to find patterns in massive data sets. Find a detailed answer here on whether coding is necessary for data science.
Can data science be automated?
While some data science operations, such as data pretreatment and cleaning, can be partially automated, others, including feature selection, model construction, and interpretation, still call for human knowledge. Automation can speed up and improve the process, but it must take a different place than a qualified data scientist who can judge and understand the results.
10Pie Editorial Team is a team of certified technical content writers and editors with experience in the technology field combined with expert insights. Learn more about our editorial process to ensure the quality and accuracy of the content published on our website.