
Push and pull technology in software engineering is a popular approach for exchanging data between two distinct entities, client and server. While the pull model works on the request-response paradigm, the push model works on the publish-subscribe paradigm.
For example, if you read a newspaper daily, you can either purchase it from a local seller or subscribe to it once and get it automatically delivered to your home. The former is an example of Pull technology, and the latter is an example of Pull technology.
Keep reading this guide to understand more about this example and know about the differences between push vs pull technology.
Table of Contents
What is Pull Technology?
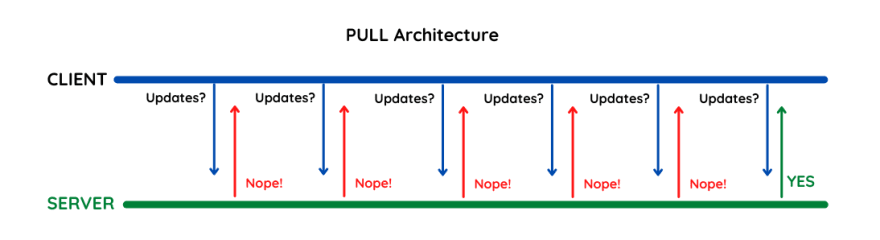
Pull Technology is a network communication style where the client requests the server for data, and then the server responds with the requested information. This technology works on a request/response paradigm.
With our previous newspaper example in the introduction, when you were going to purchase a newspaper from the local seller, you requested that they sell the newspaper and they responded to your request by selling it.
This is similar to pull technology, also known as Polling. You ask for data by typing a URL into your browser’s address bar, and it takes your request to the server over the Internet, and the server initiates the transfer of information.
Relevant resources:
Examples of Pull technology
Internet search engines
All internet search engines like Google, Yahoo, and Bing use pull technology. You enter your request to find a valuable site by typing a URL in the browser’s search box, and the browser then carries your request to the server.
Upon receiving your request, the server will send you back the required information as a response.
Companies with restricted repositories
Several companies have restricted repositories to which all employees are denied access. For example, Apple doesn’t allow product development teams to communicate with other people regarding ongoing projects.
However, if anyone needs to gather specific information to continue their task, they need to apply Pull technology.
They request the server for certain information, and the server decides whether to provide them with it or not.
RSS feeds
RSS (Really Simple Syndication) feeds work on a pull model, where the client/user of the RSS reader app requests data transfers. They then need to continue checking/polling the server periodically for the latest content; without that, the server won’t send any information.
However, this constant polling causes severe bandwidth or traffic overhead for the RSS feed servers. It further results in numerous RSS feeds shutting down or reducing services as they couldn’t handle the bandwidth demands.
To solve this problem, RSS started using the WebSub protocol, an example of push technology.
What is Push Technology?
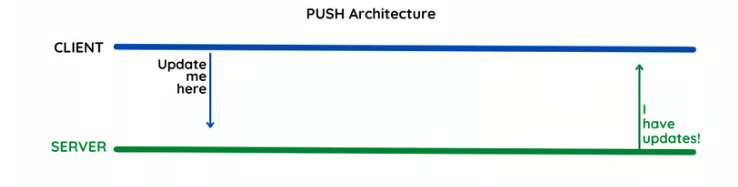
Push technology is a network communication process in which a server initiates data transfer to the recipient without their explicit request. It works on a publish-subscribe model.
In this model, a client subscribes to specific channels hosted by a server. Whenever new content is added to these channels, it is automatically “pushed” to the subscriber.
Let us continue with the previous newspaper example. The other option for reading your favorite newspaper was to subscribe to it once and get daily updates.
This is similar to push technology. Once you subscribe to a newsletter, the server keeps sending your daily news without you requesting them to send it every time.
Examples of Push technology
Email systems use Push technology to send messages to receivers automatically with the help of SMTP. It is a push protocol that is used when sending an email to build a connection with the recipient’s email server and actively push email messages.
These sender and receiver servers are called MTA (Mail Transfer Agent). Once a connection is built, the MTA doesn’t need to wait for the recipient’s email client to request or pull the message from the server.
However, once the mail is received by the recipient’s email server, the email client can pull the message from the server using protocols like POP3 or IMAP, which follow the Pull Model.
Providing system updates
Users often request system updates on the server to update their device to the latest version. However, it is not just one user; thousands of users have been doing the same thing over the period.
If you are implementing pull technology, a large number of requests will put an unnecessary load on the server infrastructure.
Therefore, they use push technology, where users automatically get notifications for updates on their devices. It eliminates the constant update requests from clients, reduces server load, and allows the proper functioning of other processes in your application server.
Cloud messaging
Cloud messaging refers to the way of informing users about new data or updates related to an application. This push notification mechanism is useful when some or all of the app’s data is managed by a company’s server rather than fully stored on the user’s device. With remote notification, companies can decide when to initiate and push a notification to the user’s device without a request.
For example, a messaging app uses remote notifications to update users whenever there’s a new message on their device. The user will receive the notification even when the app isn’t running on the user’s device.
Another example includes a calendar app, which can push notifications about an important event to the user’s device.
All these notifications are received by users automatically without the requirement of constant polling or checking for new data.
Push vs. Pull technology for mobile and web applications
Mobile app programmers need to think differently about application design today than traditional web applications, especially with the pull and push technology. The “Pull” model, where clients request the server for data, may not always be suitable for mobile applications, especially with an increased number of mobile users.
If all the users use pull technology to request data, there will be a huge number of requests hitting the network and servers, resulting in traffic overhead.
On the other hand, the “Push” model doesn’t require mobile users to send information requests. It automatically sends or pushes content updates to mobile devices using lightweight, integrated messaging services. This messaging service can be scaled up to meet the rapid increase in mobile demands.
In most cases, using a Push model in mobile applications is better than the Pull model because of its efficiency, and approach to providing a better user experience.
FAQs
1. What is the difference between push and pull technology?
The difference between push and pull technology lies in the way data is shared. The pull model works in a request-response manner, where the user requests information from the server, and the server responds to their request by providing the required information.
On the other hand, the Push model works in a publish-subscribe manner, where once a user subscribes to a channel, they get continuous updates without user requests.
| Pull technology | Push technology |
| The user requests information from the server by placing a URL on the search bar of any web browser, and the server responds to the request by providing the required information. | The user subscribes to a channel on the server, and without any requests, whenever new content is published, the server pushes it to the user |
| For example, web browsing | For example, newsletters and push notifications in mobile apps |
Here’s an interesting example shared by an expert on Reddit to help you understand the difference between push and pull technology.

2. Why is HTTP a pull protocol?
HTTP is a pull protocol because it cannot transfer data to users via existing persistent connections. It works on request-response protocol, so a server can send a response only when it has received a request from a client beforehand.
Moreover, HTTP is a stateless protocol, which means every request-response cycle is self-contained and unique, with no persistent connections. So, the server cannot use such connections to send data to clients as it becomes available.
To overcome the limitations of the HTTP Pull-based model, HTTP WebSockets was introduced. Some of HTTP’s limitations include its inability to implement real-time updates or push notifications to clients and its inefficiency of frequent data exchange. HTTP needs to handle a large number of concurrent requests, which can strain its resources and scalability.
3. Is SMTP push or pull?
SMTP is a push protocol. It starts transferring the email messages to the receiver’s email server itself without waiting for a request or pulling the email. In SMTP, the sending email server or client initiates the data transfer by establishing a connection with the recipient’s email server. Once the connection is established, the sending server actively pushes the email message data to the recipient’s email server.
The push of email data from the sender to the recipient’s server happens asynchronously without waiting for the recipient to request the email. This push model ensures efficient and timely delivery of email messages.
However, after the delivery of the email message to the recipient’s email server, the client can then pull the message from the server using pull protocols like POP3 or IMAP.
4. Is HTTP push or pull?
HTTP is a pull application because the client actively retrieves data, rather than the server pushing unsolicited information.
5. Is HTTP secure or HTTPS?
HTTPS is more secure than HTTP.
HTTP is a non-encrypted connection, which is fine if you are googling things or visiting a public website that doesn’t require you to send any login information to it.
On the other hand, HTTPS is an encrypted connection that uses TLS (SSL) to encrypt HTTP requests and responses. It not only encrypts your conversation, but it also encrypts the username and password that are sent, and it prevents people from eavesdropping.
6. Why is TCP used for HTTP?
TCP is used for HTTP for transferring data packets accurately, quickly, and in the correct order. Before exchanging an HTTP request-response pair between client and server, a TCP connection must be established.
When HTTP wants to send a message, it streams the contents of the message in order through an open TCP connection. TCP then takes the data, chops them into little chunks known as segments, and transports them across the internet inside envelopes known as IP packets.
Each of these packets consists of an IP packet header (usually 20 bytes), a TCP segment header (usually 20 bytes), and a chunk of TCP data (0 or more bytes).

Somrita Shyam is a content writer with 4.5+ years of experience writing blogs, articles, web content, and landing pages in multiple domains. She holds a master’s degree in Computer Application (MCA) and is a Gold Award winner at Vidyasagar University. Her knowledge of the tech industry and experience in crafting creative content helps her write simple and easy-to-understand tech pieces for readers of all ages. Her interest in content writing began after helping PhD scholars in submitting their assignments. Later in 2019, she started working as a freelance content writer at Write Turn Services, and has worked with numerous clients, before joining Experlu (An UK based accounting firm) in 2022 and working as a full-time content writer in GigDe (2022-2023).